2019/6/5 今年我们有同学拿到了腾讯云和 Azure 的实习,所以未来在云计算上我们会有更多的领路人,来带领团队在这个方向进行探索。MAE 虽然还没做出来,但 k3s 的发现让我们在服务器上实现了自由,相信很快就会设计出下一代的 MAE 架构。
Muxi App Engine,简称MAE,是木犀的私有PaaS方案,也是木犀云的重要组成部分。MAE主要基于Docker和Kubernetes,为木犀所有应用的构建、部署、监控和扩容提供了一个统一的入口,让我们能专注于服务本身的开发。同时MAE也为木犀提供了一套标准化的运维流程,使得团队开发中的工程化程度进一步提高。
说的这么厉害,那如果你是一个技术小白,我应该如何来解释MAE呢?
TD;LR
比如我们有一个应用,华师匣子。华师匣子是由很多的服务构成的,比如成绩服务,课表服务,图书馆服务等等。每个服务都实现了对应的接口。我们使用Docker来运行这些服务。Docker是一种容器技术。我们可以简单的理解为一种沙盒环境。这些容器的存在,已经很大程度上方便了我们的部署。因为容器可以实现系统资源的隔离,使得服务器上可以同时运行很多不同的服务,而相互不打扰。
但手动部署容器,还是太复杂了。我们要登录服务器手动部署容器。容器如果出现问题,我们也需要亲自去重启。如果我们需要横向拓展,部署多个相同的容器以应对高负载,也需要一个个去手动部署。这个时候就需要一个调度者来帮我们自动完成这个任务。
我们可以把MAE理解为容器的调度者。我们在MAE中新建一个应用和下属的服务,填写相关的信息。比如我们只要提供Docker镜像的地址,就可以一键部署。MAE会帮我们将容器部署到合适的服务器上。如果容器因为某些原因崩溃了,MAE会自动重启容器。如果我们需要横向拓展,那只要在控制台里填写一下需要拓展的数量就可以了。如果需要更新代码,我们只需要提供镜像的新版本号,MAE会自动终止旧版本的容器,新建新版本的容器。一切都是这么简单。可以自动化的事情,我们都会做到自动化。
MAE提供Web UI和CLI。Web UI主要用于日常的使用以及查看监控数据。CLI适合在shell脚本等自动化环境下使用。
MAE带来的最大变革是,今后我们的应用从一开始就应该按Cloud Native的思路去编写。要拥抱云计算,我们必须编写Cloud Native的应用,具体的说,使用微服务架构,写无状态的功能单元,容器技术,将数据库等等持久化的组件作为单独的部分等等,都是Cloud Native的体现。只有这样,我们的应用才能和目前公有云和私有云的基础设施完美结合。
下面就是纯粹的技术讨论了,请耐心阅读。
MAE的技术选型
简单的说,就是Docker和Kubernetes。Docker是容器技术的实现,Kubernetes主要提供了容器编排管理的功能。上一节中说到的大部分自动化功能,都是Kubernetes实现的。MAE中需要我们研发的主要是MAE API服务、Web UI还有CLI程序。除了这些,还有就是在MAE中实现一套最适合我们的对应用的抽象。这套抽象是非常重要的。Kubernetes的概念并不是所有人都可以理解的,也没有必要对使用者暴露最底层的概念。PaaS的用户是从是应用和服务这些逻辑上的概念去看待问题的。所以MAE就提供了针对应用和服务的抽象,并且和Kubernetes整合起来。
MAE的组成部分
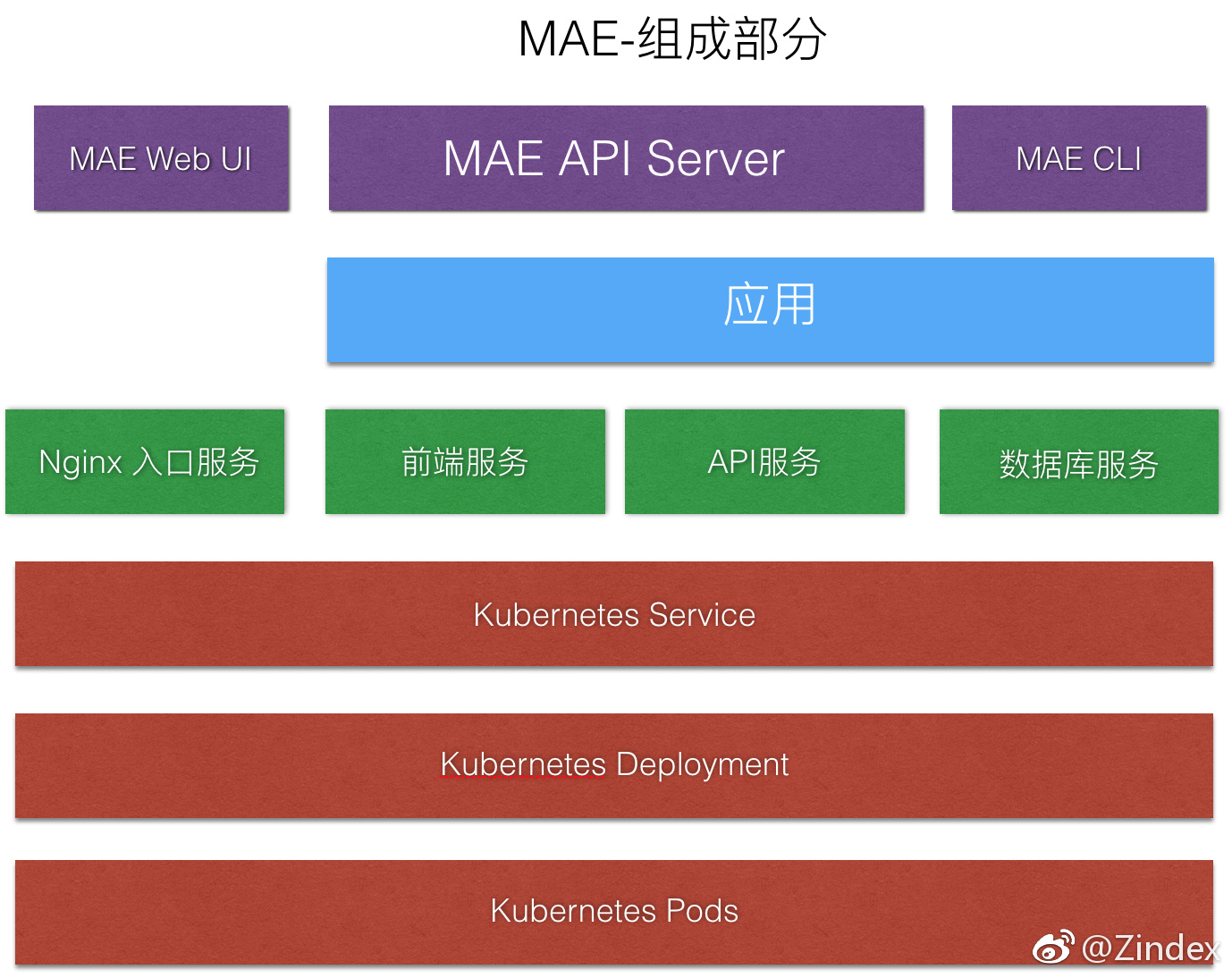
MAE的组成,从上到下,大致有三层:
- MAE服务层 MAE服务层是暴露给用户的一些服务。MAE API Server是MAE是中枢。负责和底层的集群通信,保存应用配置等等。MAE Web UI提供了一个Web界面,用户可以通过Web UI对MAE发出指令,查看监控数据。MAE CLI是一个命令行程序,提供了从命令行和API Server通信的渠道。
- 逻辑应用层 这一层是抽象的应用层。也就是我们概念上的应用。因为实际的集群中是没有应用概念的(当然Kubernetes的Services+Namespace已经非常接近了),所以我们需要在这里提供对应的抽象。我们可以在MAE中新建应用,然后配置这个应用对应的服务。MAE中的服务(以后简称MAE服务,区别于Kubernetes Service),其实就对应一个微服务。一个应用由至少一个微服务构成。MAE服务是用户可以控制的部署的最小单元。我们可以对某个MAE服务单独进行拓展。比较特殊的MAE服务就是Nginx入口服务,这个服务为所有应用提供反向代理,同时也作为一个MAE下的服务,被MAE部署。
- Kubernetes层 Kubernetes这层就是底层的实现层了。包括了Service,Deployment和Pods。其中Service和Deployment在上层共同支撑了MAE服务。Pods则属于最底层的调度单元。在MAE层是完全不可见的。一个Pod由至少一个容器构成。
MAE的流量分发
那么作为一个分布式系统,一个用户的请求究竟是经过怎样的路径,到达最底层的Kubernetes Pod的呢?
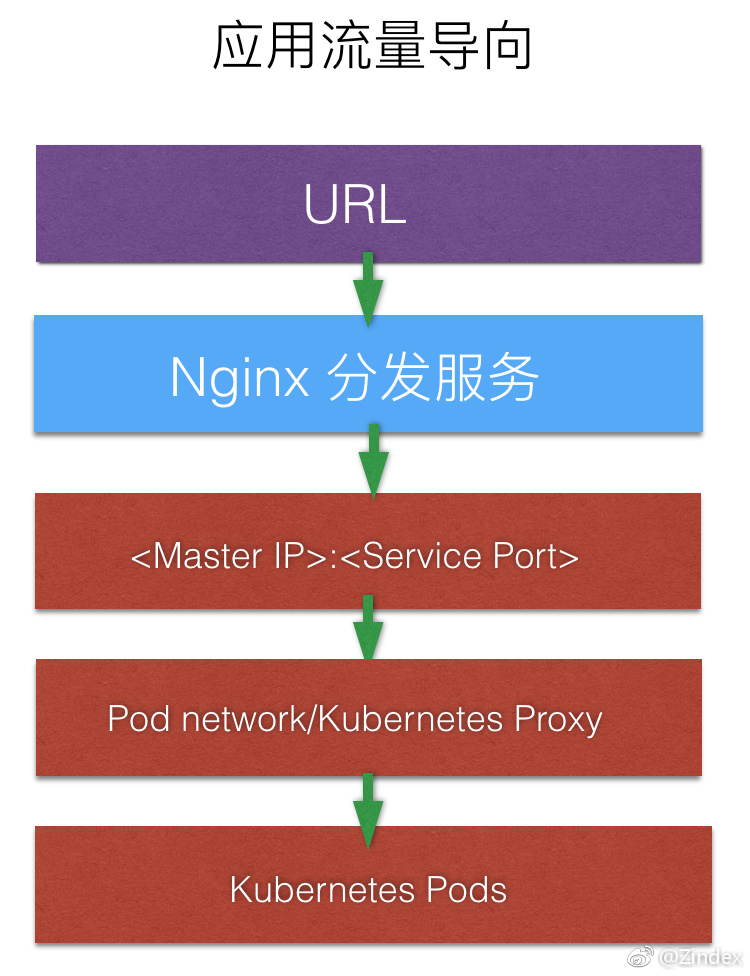
首先DNS把域名解析到Kubernetes的Master节点的公网IP上,然后部署在Master节点上的Nginx入口服务接管,Nginx根据MAE应用设置的域名和URL规则,将这个请求转发到对应应用的某个服务上。Kubernetes的服务都是可以通过<Master内网IP>:<Service Port>来进行访问的。然后Kubernetes proxy用iptables规则,将请求转发到某个节点上的Pod。
由于Kubernetes proxy提供了均衡负载,我们不用再操心如何分配流量到服务下属的多个Pod中的某一个这样的问题。今后可以做的优化是,实现Kubernetes Master节点的高可用,也就是同时部署多个Master节点。这样的话就需要在Master节点之上再实现一个均衡负载。
MAE的实现细节
MAE做的抽象,一个是应用,应用之下是服务。对于这两个抽象,应该各自保存一些什么样的数据,这属于MAE的实现细节。
每个应用需要的信息有,应用名,域名,Nginx转发规则,应用下属的服务列表。
每个服务需要的信息有:服务名,当前镜像版本,镜像仓库地址,Github仓库地址,Kubernetes Service和Deployment需要的全部信息,当前服务属于哪个应用,授权管理当前服务的用户列表。
因为服务是部署的最小单元,因此相对来说服务是MAE中比较核心的一个部分。MAE需要将数据库中保存的服务信息,自动转化为Kubernetes需要的.yaml文件。将数据库中保存的应用信息,自动转化为nginx的配置文件。这是实现上需要去考虑的一个问题。
另外,现在还需要仔细考虑的一点,MAE在全局/应用/服务这几个层面分别需要哪些监控数据。
MAE时代的部署工作流
部署服务之前,首先我们要构建镜像(构建之前可以引入CI,测试通过才可以构建镜像)。给镜像打上版本号,然后发布到云端的镜像仓库(可以用阿里云/蜂巢/Daocloud)。之后我们就可以在MAE中为某个服务新建一次部署了,填上新的版本号,点击部署,就启动了一次部署了。得益于Kubernetes超强的部署能力,我们可以回滚、暂停、继续每一次部署。
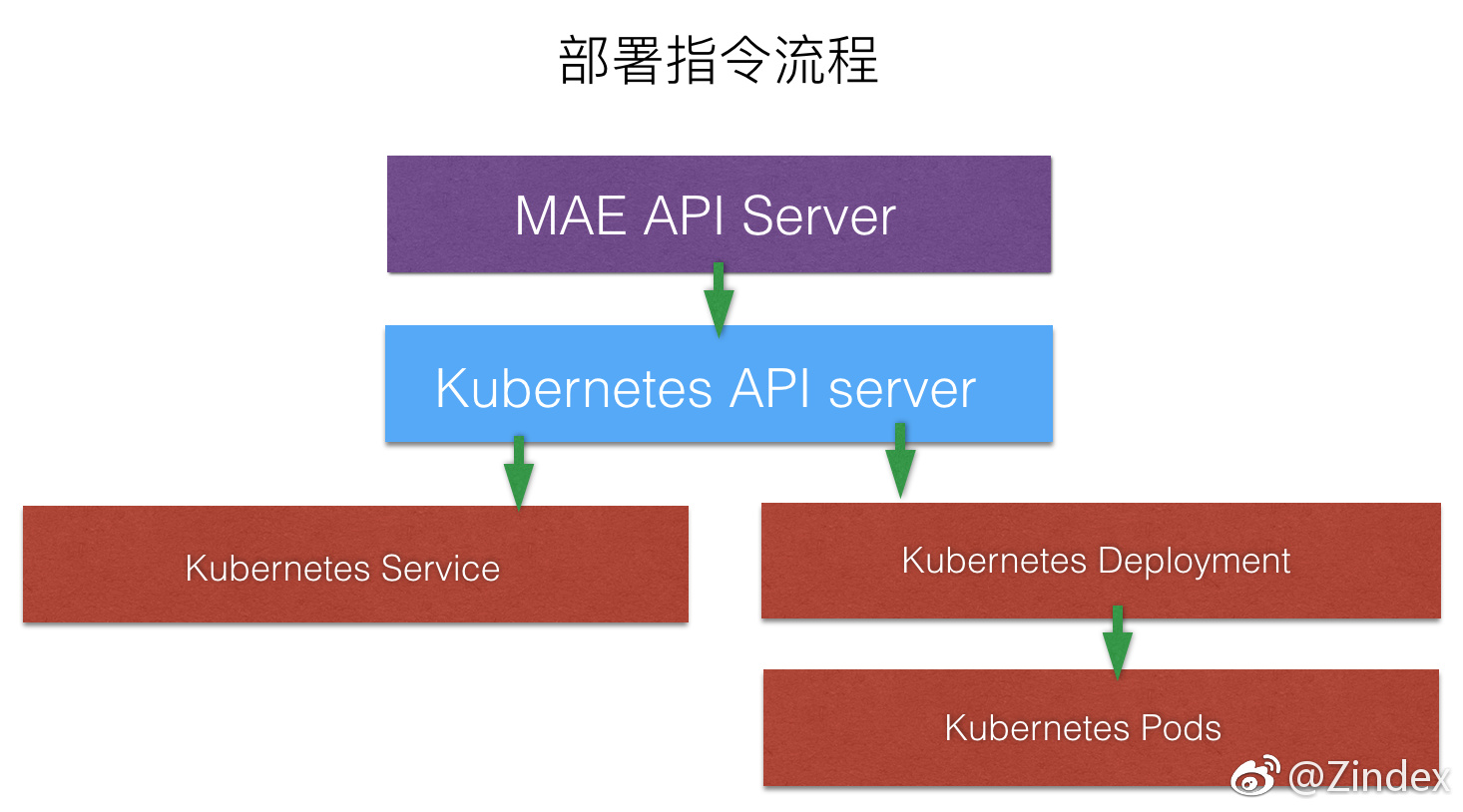
MAE的API Server把服务目前的配置转换为.yaml格式,向Kubernetes API Server发送请求。然后Kubernetes会进行相应的处理。和Service相关的就调整Service,和Deployment相关的就调整Deployment。最终服务更新到目标状态,部署完成。
MAE的物理节点组成
MAE的逻辑组成已经介绍了,那MAE和具体的云主机之间是什么关系呢。请看下图:
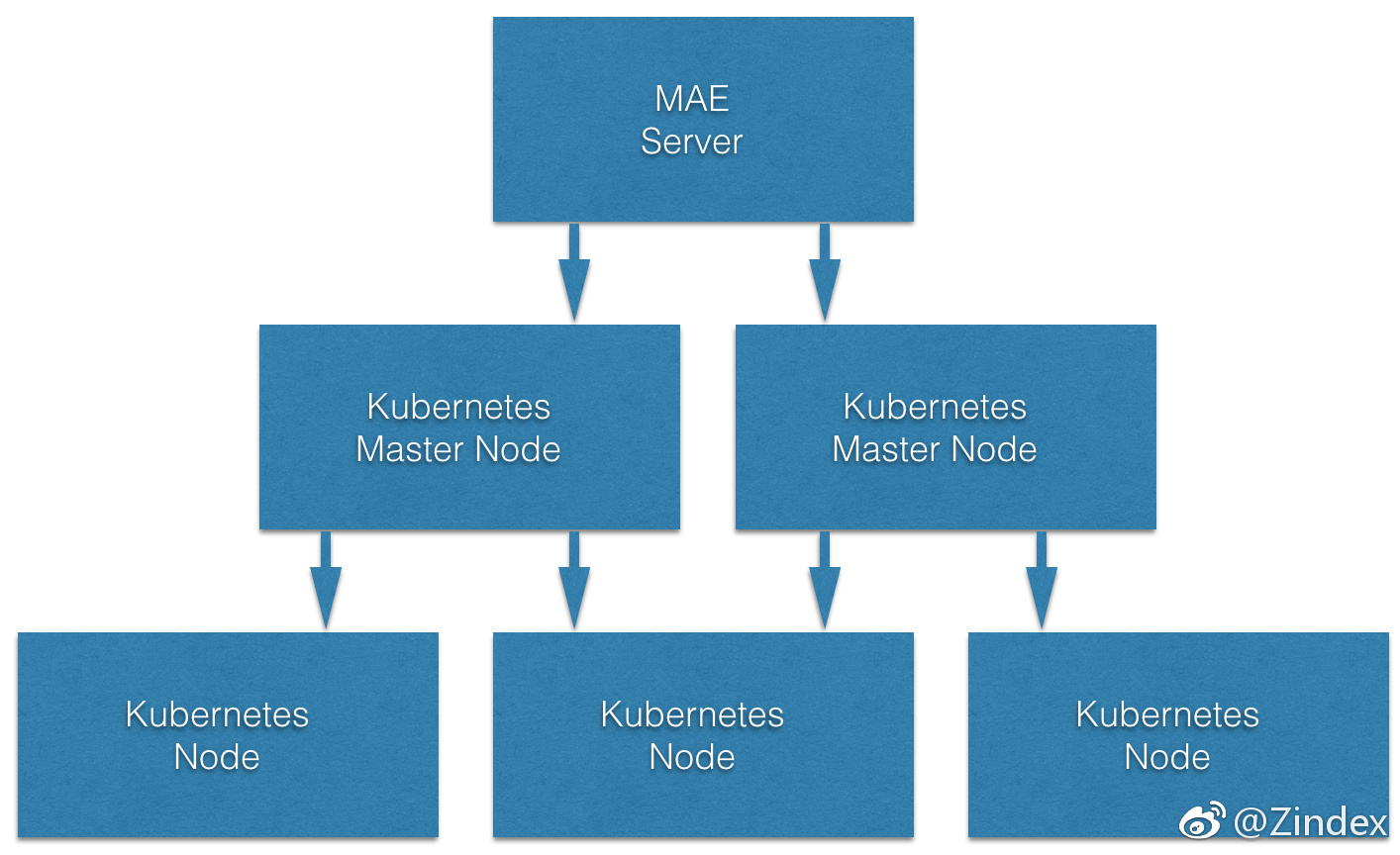
图中的一个框对应一台云主机。其中Master节点目前只打算部署在一台机器上。今后会做高可用(具体要看kubeadm的支持情况,自己部署HA也是可以的,参见这篇博客)。Kubernetes Node是负载Pod调度的机器,也就是分布式系统主从节点中的Slave节点。Kubernetes的Pod可能会被调度到其中任意一台机器上。因此应用在物理上运行在哪个节点,在MAE中并没有太多的意义。
MAE的Server在理论上会单独部署在一台服务器上,MAE Server如果出现问题,其实并不影响当前集群的正常运转。Kubernetes的Master节点才是真正负责调度和管理的,因此才会有做高可用的打算。
MAE时代的前端服务化
MAE要求一个应用由几个服务构成。这给了我们一个机会,去改进目前的前端代码部署流程。目前的前端代码是放在后端容器中部署的。每次部署需要后端工程师参与,或者使用配置复杂的Webhook。前端代码部署时需要重启后端容器,因此无法实现无副作用的前端部署。MAE架构下,我们将前端作为一个单独的服务。这个服务主要接受的是从Nginx入口服务转发而来的需要返回HTML的请求,也就是我们一般所说的View层,或者说同步路由层。技术上我们选用Nodejs来实现前端的服务。
所以今后前端工程师的产出就是前端代码以及Nodejs服务端代码(主要是路由)。两者在同一个仓库中,部署在同一个容器中。
这样的好处是,前端代码部署时只需要构建前端服务的镜像,然后在MAE单独部署就可以了。和后端完全解耦。前端工程师也可以借助MAE提供的强大的运维能力,来优化自己的工作流。
前端工程师接管View层,给我们的应用带来了更大的可能性。服务端渲染前端组件变成了非常自然的选择。前端工程师控制的范围扩大,提供了更多发挥的空间。比如前端工程师可以对静态资源缓存,CSRF等等进行更好的控制。
MAE的主要API以及CLI工具命令
API在Web UI框架确定之后就可以比较清楚的写成文档了,这里只列一下主要的API。
应用层API
- 应用列表/信息
- 应用网络配置更新
- 监控信息
服务层API
- 服务列表/信息
- 部署服务新版本
- 横向拓展服务
- 回滚、暂停部署
- 监控信息
CLI
CLI提供了和主要API对应的命令。命令需要验证的话,可以通过mae login这样的命令来进行。
木犀云的其他产品展望
Muxi Database Service(MDS)
提供Mongo,Redis等云数据库服务。实现了数据自动备份,多节点高可用等特性。
Muxi Storage Service(MSS)
基于Ceph的分布式对象存储。负责大文件的存储。比如图片、文档等。
鹊桥
木犀接口管理平台。提供了接口的云端管理和Mock服务。
Muxi UI(MUI)
基于Vuejs的UI组件库。适用于中后台前端应用的快速开发。
写在最后: Why Cloud?
为什么木犀要拥抱云计算?为什么我们要自建私有PaaS平台?
首先,在当下,计算能力,已经和水电煤一样,成为了一种基础设施。作为小团队,使用现成的基础设施,从成本上以及灵活性上都是最佳的。
虽然我们使用了IaaS服务,但我们还是可以把云主机当做物理主机来使用,我们完全可以实施云计算出现之前时代的传统运维。运维工程师负责服务器的环境,开发工程师把代码交给运维工程师部署。数据库等服务和业务逻辑部署在同一台机器上,等等等等。很明显,坚持这种做法,将云计算理解为虚拟主机,是非常不明智的。
既然已经用上了IaaS,那就要利用现有的微服务理论和Docker等等容器技术,打造更加原生的云端体验。我们将代码拆成一个一个单元,将有状态和无状态的服务分离。部署时容器让我们不用在意服务端的环境隔离。Kubernetes让我们不用手动管理容器的生命周期。
开发MAE是为了解决目前团队部署流程中存在的问题。自建的PaaS平台可以最大程度提供个性化的使用体验。也给我们机会去对Kubernetes等开源技术进行探索和研究,并且用到生产环境之中。
围绕木犀云而进行的一系列的研究,是木犀拥抱云计算的最好方式。我们不仅要享受云计算的好处,同时也要参与其中,深入的理解技术细节。相信未来我们在云计算上的发展会有无限的可能。