本文介绍了CMU 15-441的课程项目Liso的一个实现。主要介绍了请求流程、Client状态机模型、Dynamic Buffer数据结构等等。SSL相关的部分没有涉及。
实现
我看的是这位同学的实现。
一个HTTP静态文件请求的流程
首先我们拿一个简单的静态文件请求来梳理一下Liso的流程。在liso.c的main函数中,有这个服务器的主循环,这个循环每次做的事情就是用select来查询I/O事件。select之后,我们首先做的是查看listenfd是不是有read事件,如果有就accept这个连接。然后把连接加入到连接池里。一个连接的初始状态是READY_FOR_READ。
listenfd是连接池中的第一个item,也是一直存在于连接池中的一个描述符。
在循环的最后,我们会调用handle_clients对连接池中可读和可写的描述符依次进行处理。具体的方式就是遍历连接池,如果一个连接是可读的,并且状态是READY_FOR_READ,我们就读取这个连接中的数据。
每次从每个连接读取的数据是固定的长度,比如4KB。这是为了控制I/O的粒度,不让server在一个连接上花太多时间,使得新的连接请求被阻塞。
我们把收到的数据,放到client_buffer里面。然后看一下HTTP的Header是不是已经读取完全了(调用handle_recv_header判断读取到的数据中是否有"\r\n\r\n")。如果HTTP的header还没有读取完全,那就继续留在READY_FOR_READ状态,等待下一次循环。
如果Header已经读取完全了,我们就调用handle_http_request处理请求,在处理请求时,我们把要返回的数据写在client_buffer里,然后调整这个client的state到READY_FOR_WRITE。
在handle_clients的循环中,如果我们发现一个client的状态是READY_FOR_WRITE,我们就会把client_buffer里相关的数据写到客户端,然后根据这个连接的ConnectionHeader选择关闭或者保留这个连接。
这就是一个简单的HTTP静态文件请求的流程。
连接池的数据结构
typedef struct {
/* Client pool global data */
fd_set master; /* all descritors */
fd_set read_fds; /* all ready-to-read descriptors */
fd_set write_fds; /* all ready-to_write descriptors */
int maxfd; /* maximum value of all descriptors */
int nready; /* number of ready descriptors */
int maxi; /* maximum index of available slot */
/* Client specific data */
int client_fd[FD_SETSIZE]; /* client slots */
dynamic_buffer * client_buffer[FD_SETSIZE]; /* client's dynamic-size buffer */
dynamic_buffer * back_up_buffer[FD_SETSIZE]; /* store historical pending request */
size_t received_header[FD_SETSIZE]; /* store header ending's offset */
char should_be_close[FD_SETSIZE]; /* whether client should be closed when checked */
client_state state[FD_SETSIZE]; /* client's state */
char *remote_addr[FD_SETSIZE]; /* client's remote address */
/* SSL related */
client_type type[FD_SETSIZE]; /* client's type: HTTP or HTTPS */
SSL * context[FD_SETSIZE]; /* set if client's type is HTTPS */
/* CGI related */
int cgi_client[FD_SETSIZE];
} client_pool;
每个socket连接在建立之后都会被放到client_pool里面。连接池在概念上就是一个大的数组。实现的时候,我们把每个连接相关的属性各自设置为一个相同大小的数组。每个item的属性就是属性数组中相应index的值。比如我们可以通过client_pool->client_fd[i]拿到第i个请求的fd。其他属性也是类似的。
FD_SETSIZE这个常量是这个server并发连接的最大值,这个常量的大小一般是1024。这个值是操作系统设置的。这个连接池里除了各个连接相关信息的数组之外,还有几个fd_set类型的全局属性,其中master里保存了整个连接池的描述符。这也就是我们select循环时监听的目标。需要注意的是CGI连接在建立之后,也会被放到这个连接池中(client_fd指向发起CGI请求的客户端,cgi_client指向CGI连接,这个连接在CGI处理完后会被我们从连接池中清除)。这样我们就可以利用select对CGI请求进行事件驱动的异步处理。
client的状态机模型
我们知道有限状态机由一组状态和一组转移组成,在Liso里,一个client的状态有以下几种:
typedef enum client_state {
INVALID,
READY_FOR_READ,
READY_FOR_WRITE,
WAITING_FOR_CGI,
CGI_FOR_READ,
CGI_FOR_WRITE
} client_state;
在讲具体的状态模型之前,我们要把连接池中的连接分为两种,一种是客户端的连接描述符,一种是CGI连接。这两种连接的在连接池中的数据结构是相同的。
在处理HTTP请求时,如果一个请求是CGI请求,我们就会fork一个进程,获取CGI的文件描述符,然后调用add_cgi_fd_to_pool函数将这个描述符加入到连接池中。加入操作的核心代码是:
/* Update client data */
p->client_fd[i] = cgi_fd;
p->state[i] = state;
/* CGI */
p->cgi_client[i] = clientfd;
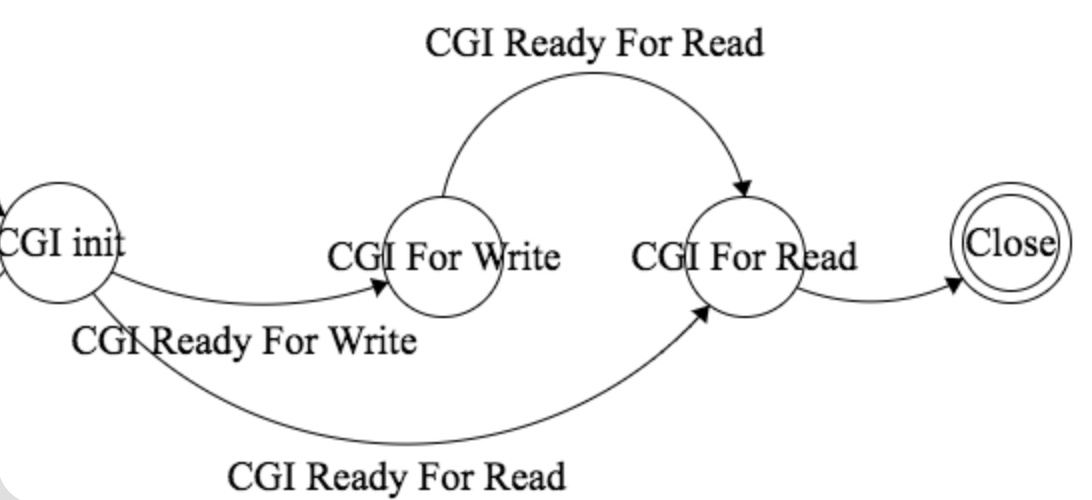
所以这个连接和普通的连接一样,都有client_fd属性,不同的是这个连接有一个cgi_client属性,指向CGI连接的文件描述符。所以在处理CGI请求的时候,一个连接在连接池中有客户端连接和CGI连接两个item。CGI连接的状态仅仅只是在CGI_FOR_READ和CGI_FOR_WRITE之间转换。在CGI连接可读,并被写到客户端之后,我们会从连接池中清除这个CGI的item。所以客户端连接和CGI连接的状态机模型应该分开讲述。
客户端连接状态机模型
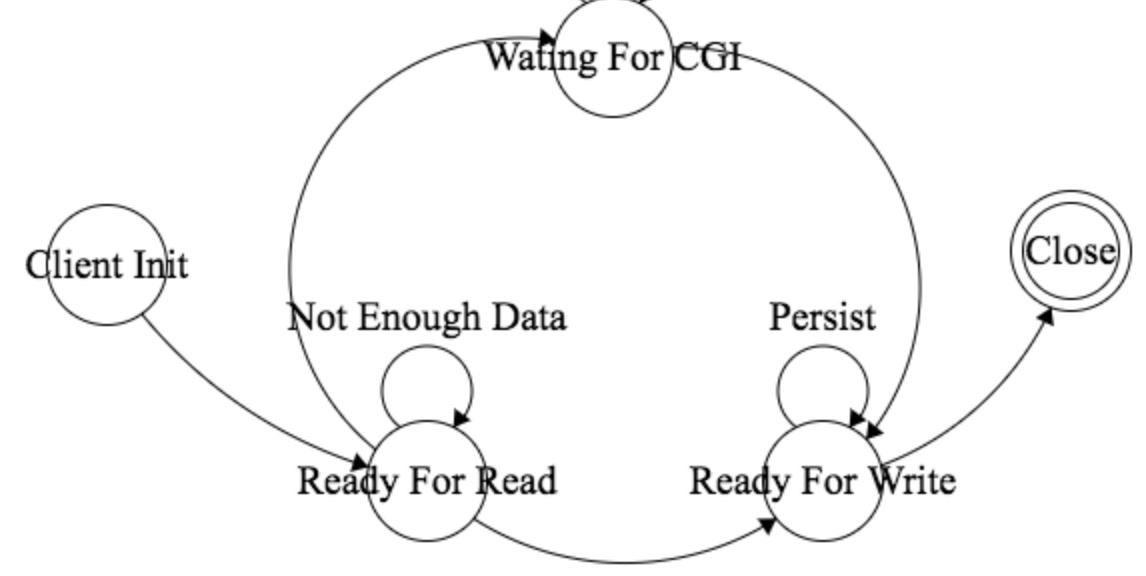
客户端连接,如果是CGI连接,会比静态资源请求多一个WAITING_FOR_CGI的状态。这里我们需要注意的是,我们在读取一个连接的数据时,如果是一个POST请求,一般会分很多次。如果读取之后数据不够,这个连接的状态就会停留在READY_FOR_READ,等待下一次select循环。直到读取到足够的数据(根据Header里的content-length)之后,才把这个请求的状态转移到READY_FOR_WRITE。
CGI连接状态机模型
长连接
我们知道HTTP的Header中有一个Connection字段。如果这个字段的值为close,在READY_FOR_WRITE状态时,如果我们写完了当前请求所请求的数据,我们就关闭连接。如果这个字段的值为keep-alive,连接会经过Persist转移,重新进入READY_FOR_WRITE状态。
在写完数据之后依然保持READY_FOR_WRITE状态,不关闭连接,这就是我们常说的HTTPkeep-alive长连接。在这种情况下,server假定的是在未来的某个时间节点,这个客户端上还有数据可以读取,所以我们暂时不关闭连接。
举例说一下HTTP长连接的用途:如果一个域下有多个资源需要请求,浏览器会复用同一个TCP连接。也就是说服务器可以在一个TCP连接上进行多次HTTP请求。这样有利于减少网络延迟和服务器的并发压力。
Dynamic Buffer数据结构
Dynamic Buffer数据结构是对普通buffer的封装。为了应对HTTP请求中长度不一定的二进制数据,我们需要一个封装良好的buffer结构,让我们方向的使用,不用担心内存管理问题。
typedef struct dynamic_buffer{
char *buffer;
size_t offset;
size_t capacity;
size_t send_offset;
} dynamic_buffer;
dynamic_buffer类型用struct封装了一个新的类型,buffer指向实际存储数据的buffer。另外还有offset、capacity和send_offset这些属性来辅助内存管理。offset让我们掌握目前buffer的实际容量是多少。capacity让我们可以掌握buffer占用的内存大小,方便动态的扩容。作者说这个设计是模仿的C++ vector STL。
CGI相关
Liso中用来描述一个CGI执行进程的数据结构是这样的:
typedef struct CGI_executor {
int clientfd;
int stdin_pipe[2]; /* { write data --> stdin_pipe[1] } -> { stdin_pipe[0] --> stdin } */
int stdout_pipe[2]; /* { read data <-- stdout_pipe[0] } <-- {stdout_pipe[1] <-- stdout } */
dynamic_buffer* cgi_buffer;
CGI_param* cgi_parameter;
} CGI_executor;
里面主要的成员除了cgi_buffer和用于传入环境变量的cgi_parameter之外,stdin_pipe和stdout_pipe两个成员值得注意。
pipe
stdin_pipe和stdout_pipe两个成员代表了两个pipe。pipe是Linux中的一种通信机制。一个pipe有两个fd组成,第一个代表read端,第二个代表write端。写入的数据会缓存在内核中,在读取时被取出。我们可以用pipe函数来创建一个pipe,pipe中的两个文件描述符在fork时也会被复制。所以pipe可以被作为一种进程间通信的手段。
关于pipe的更多信息请参考The Linux Programming Interface Chapter 44
我们的server主进程要和CGI进程通信,就是通过pipe做到的。
在CGI进程中的代码:
close(cgi_pool->executors[slot]->stdout_pipe[0]);
close(cgi_pool->executors[slot]->stdin_pipe[1]);
dup2(cgi_pool->executors[slot]->stdout_pipe[1], fileno(stdout));
dup2(cgi_pool->executors[slot]->stdin_pipe[0], fileno(stdin));
我们关闭了CGI进程中stdout_pipe的read端,把write端重定向到CGI进程的stdout,因为主进程要从这个pipe读取CGI进程的输出。
我们关闭了CGI进程中stdin_pipe的write端,把read端重定向到CGI进程的stdin,因为主进程要向CGI进程中写入一些信息,比如POST请求的body。
在主进程中,我们关闭用不到的两个fd,分别是stdout_pipe的write端和stdin_pipe的read端。
close(cgi_pool->executors[slot]->stdout_pipe[1]);
close(cgi_pool->executors[slot]->stdin_pipe[0]);
select + CGI
在CGI进程被创建之后,我们调用add_cgi_fd_to_pool函数把这个clientfd和CGI的fd一起加入到监听的连接池里面。CGI的fd是什么呢?没错,就是stdin_pipe[1]和stdout_pipe[0],stdin_pipe[1]代表着CGI进程的输入,当这个fd为可写时,我们可以向CGI进程写入数据。stdout_pipe[0]代表着CGI进程的输出,当这个fd为可读时,我们可以从CGI进程中读取数据。加入到连接池中意味着我们可以通过select来监听CGI进程的I/O事件。所以在select的handle_clients里,除了客户端可写和客户端可读之外,我们需要处理CGI可写和CGI可读两种情况。
由此我们便可以在select中根据事件,来对客户端进行处理,转移它们的状态。一个非阻塞的事件驱动Server设计已经有了雏形。
如何加强Liso
Liso距离一个工业级的Server还有很大的差距,我们可以做的改进有:
- 将静态文件I/O改造为基于线程池的设计。
- 使用
epoll代替select。 - 支持使用DSL对服务器进行配置。
- 支持Gzip。